这款模型最近真的很火,让我想起了当初kimi刚发布的时候。网上关于它的讨论基本都聚焦在“便宜,开源,创新”这几点上,对于吃瓜群众来说足以呼应他们的情绪了,但从开发者的角度来说,我们更想知道,可以从这个“自学成才”的模型中学到什么?
deepseek-R1是基于大规模强化学习进行训练的。所谓强化学习,就是完全不依赖人类给的“标准答案”来训练,而是通过与环境的互动,学习到一种策略,以最大化长期累积的奖励,就比如AlphaZero那种自己跟自己下棋、慢慢变厉害的模式。
在传统的大模型训练中,这种“自学成才”的模式没有被重视,因为太麻烦了:首先数据获取就很麻烦,要让模型在环境里摸爬滚打,还要设计奖励机制,才能逐步生成数据;而且强化学习的训练过程不稳定,不同的起点和探索方式可能会让训练结果差很多,甚至可能根本就训练不好,就像在风浪里划船。
相比之下,监督学习就像在平地上走路,不仅集中标注数据更简单,算法实现的路径也更加明确。
那这里你可能就有疑问了,能不能把这两者结合起来呢?
实际上,deepSeek团队在训练R1-Zero的时候就主打强化学习,但是他们发现R1-Zero的推理输出的内容有时候会让人看得一头雾水,要么就是重复来重复去,要么就是各种语言混在一起,让人摸不着头脑。为了改进这些问题,他们在R1-Zero的基础上加入了一点点监督微调(SFT),这才有了R1。
那么R1的表现如何呢?
由于R1模型主要对标的是其他推理模型,比如OpenAI的o1,所以想要考验它的能力,就得出一些复杂一点的、需要一层层推理才能解开的题目。重点是,这些题目得是全新的,不能在网上或者论文里找到现成的答案。我们来看几个例子。



这题可能难度还是低了点,网上的资料也比较多,但deepseek-R1给出的答案我还是比较满意的,相比GPT-4或者GPT-4o,它几乎没有幻觉,这就非常不错了。
可以对比一下ChatGPT 4o对同一个问题的回答:

虽然deepseek-R1和ChatGPT 4o都有一个幻觉,那就是孙悟空先被封弼马温,后自称齐天大圣(只要联动搜索就很容易纠正这个错误)。但deepseek-R1还是更完整的提到了“避马瘟”的谐音梗和更深入的解释了天庭的权谋,从这个角度来说体验比4o要好一些。
再来看一个网友的脑洞:

怎么样?我感觉我都可以借助deepseek写一篇硬科幻小说了,不得不说,这个推理能力还是很在线的,而且速度非常快,这可能是因为它有个特别的设计,叫混合专家(MoE)架构,通过一种“路由器”机制,只激活一部分神经元,这样就能省下不少计算成本,推理起来就更高效了。
根据网上公开的消息,R1的API定价远低于OpenAI-o1,输入token收费0.55美元/百万,输出token收费2.19美元/百万,而o1的收费分别是15美元/百万和60美元/百万。R1之所以这么便宜,不是因为补贴或者烧钱,而是技术上的创新。有了这么便宜又厉害的AI模型,自己动手撸一个AI应用也不算啥难事儿了!你看,像LangChain、Spring AI这种开源项目越来越成熟,机会也越来越多。对于专业的程序员来说,AI的更新换代简直就是“新饭碗”的代名词!已经有不少人靠转型搞AI,实现了升职加薪,开启职场“外挂模式”了!

从R1到R1-Zero, 靠的是对模型的微调,而想要发挥模型的潜能,还需要配合基于LangChain这样的开发框架所做出的应用,这些都是一名AI大模型工程师的必备技能。如果你也想要成为让大模型帮你提高工作效率,或者转换赛道到大模型行业,那么我建议你去听听知乎知学堂的大模型开发工程师课。
就我个人的体验来说,这门课讲得特别清楚,不管你是刚入行的小白,还是已经混迹江湖的老程序员,跟着老师都能学到AI大模型最新、最全的知识,听完课,还能领取AI大模型的资料,性价比超高!
尽管deepSeek-R1在文本推理和逻辑任务中表现出色,但在通用能力方面仍然存在短板。比如在函数调用、多轮对话、复杂角色扮演等任务上,它的表现就不如deepSeek-V3。而且R1也不支持多模态任务,不过这也不是重点啦。
根据网友们的反馈,尽管经过了优化,但是deepseek处理非中英文内容的时候还是不太灵光,语言混杂现象还是存在。比如你给它一个德语的脑筋急转弯,它会先翻译成中文或英文再处理,这样一来一去,不仅浪费时间,还容易出错。
另外,这个模型还特别“挑食”,对提示词非常敏感。如果给它的提示太少,它就会出现一些奇怪的状况,比如思维链过于复杂,“左右互搏”,或者输出质量明显下降;而给的提示太多,又会把它搞懵,导致输出的答案过于中庸。
在应用场景上,由于强化学习训练的评估周期较长,导致DeepSeek-R1在软件工程任务上也有些“力不从心”,哪怕是生成简单的bash脚本,也不如OpenAI的o1模型稳定了。
R1的这些问题,其实也是推理模型共同的瓶颈。比如模型的表现要看训练数据的脸色,要是遇到需要复杂或者现代知识的推理任务,它们就容易“掉链子”、卡壳。而且模型的参数量还是太大,想要在本地硬件上运行,可能还是要经过蒸馏。
R1系列模型在训练方法上确实有突破,尤其是R1-Zero完全依靠强化学习就能获得强大的推理能力,这为大模型训练提供了新的思路。而DeepSeek将模型开源,并采用宽松的MIT License,也必定会推动技术的应用,成为国产AI的新生力量。
本文转载于MSN作者:知乎,文中观点仅代表作者本人,本站仅供信息存储,如有侵权请联系本站删除。
本文来自于网络或用户投稿,本站仅供信息存储,阅读前请先查看【免责声明】,若本文侵犯了原著者的合法权益,可联系我们进行处理。本文链接:https://trustany.com/intel/1221.html













 固态硬盘性能排行榜前十名(固态硬盘耐用性排行)
固态硬盘性能排行榜前十名(固态硬盘耐用性排行)
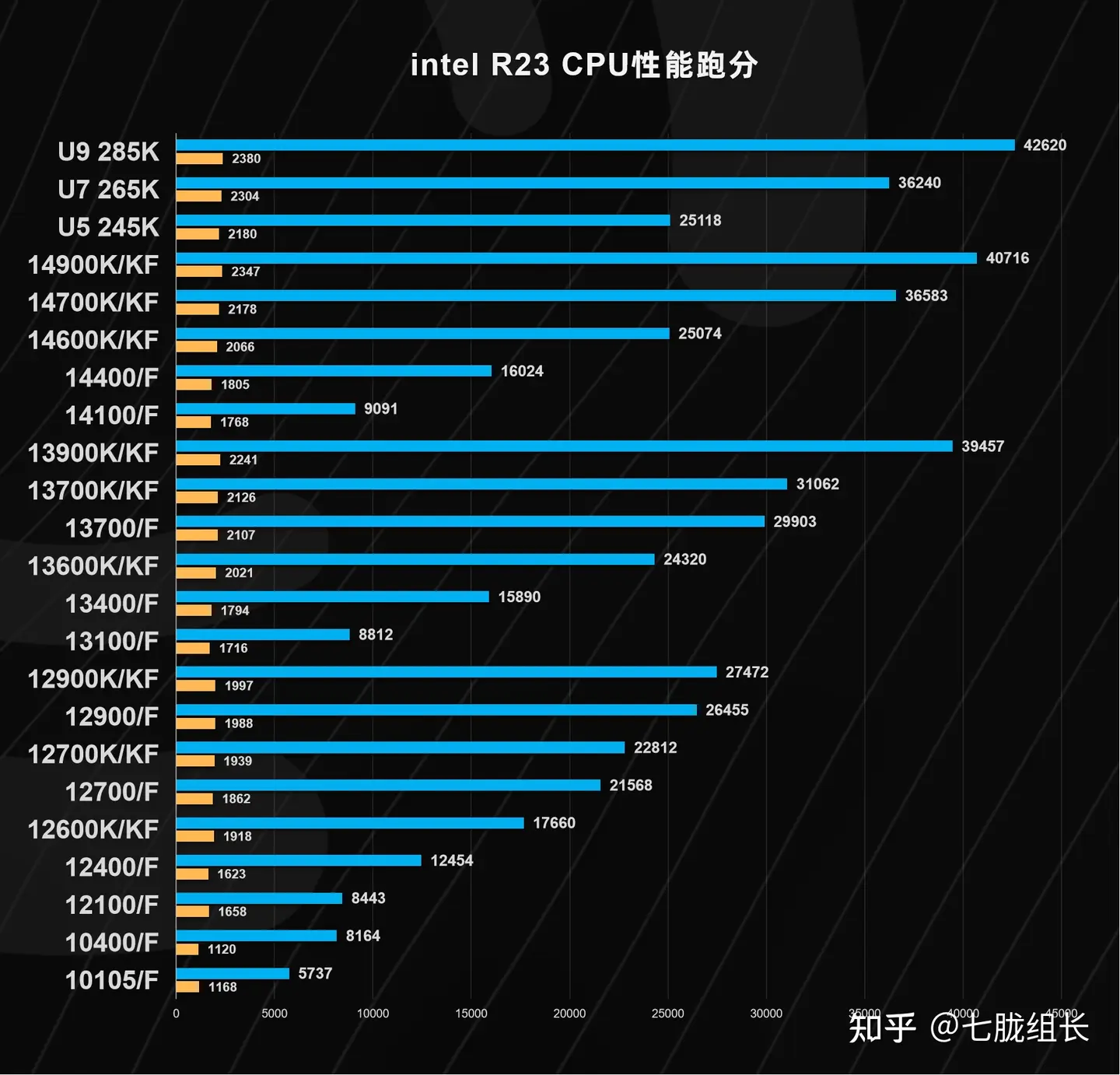 cpu性能天梯图2025(处理器排行榜2025最新)
cpu性能天梯图2025(处理器排行榜2025最新)
 兰州大学全国排名(兰州大学排名全国几位)
兰州大学全国排名(兰州大学排名全国几位)